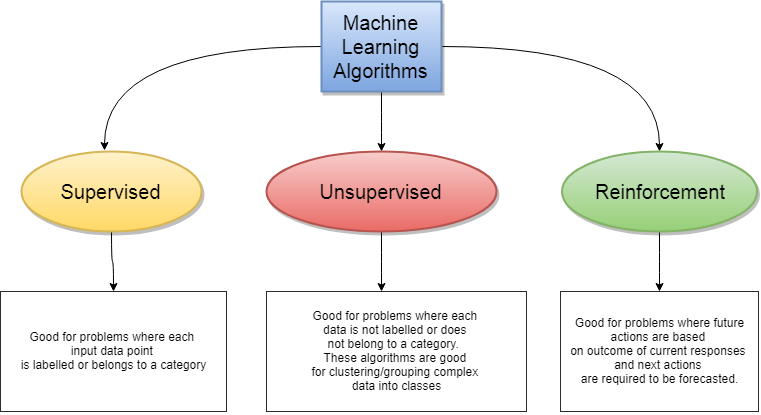
Unsupervised learning, also known as unsupervised machine learning, uses machine learning algorithms to analyze and cluster unlabeled datasets. These algorithms discover hidden patterns or data groupings without the need for human intervention. Its ability to discover similarities and differences in information make it the ideal solution for exploratory data analysis, cross-selling strategies, customer segmentation, image and pattern recognition. It's also used to reduce the number of features in a model through the process of dimensionality reduction; principal component analysis and singular value decomposition are two common approaches for this. Other algorithms used in unsupervised learning include neural networks, k-means clustering, probabilistic clustering methods, and more.
Machine LearningArtificial IntelligenceMachine learning can be defined as the ability of computers to acquire knowledge and learn new skills. Unsupervised learning is the second of the four machine learning models. The machine studies the input data – much of which is unlabeled and unstructured – and begins to identify patterns and correlations, using all the relevant, accessible data. In many ways, unsupervised learning is modeled on how humans observe the world. As we experience more and more examples of something, our ability to categorize and identify it becomes increasingly accurate. For machines, "experience" is defined by the amount of data that is input and made available.

Common examples of unsupervised learning applications include facial recognition, gene sequence analysis, market research, and cybersecurity. Deep learning describes algorithms that analyze data with a logic structure similar to how a human would draw conclusions. Note that this can happen both through supervised and unsupervised learning. To achieve this, deep learning applications use a layered structure of algorithms called an artificial neural network .
The design of such an ANN is inspired by the biological neural network of the human brain, leading to a process of learning that's far more capable than that of standard machine learning models. Furthermore, it is now possible to develop models that can automatically adapt to bigger and complex data sets and help decision makers to estimate impacts of multiple plausible scenarios in a real time. A subset of machine learning is closely related to computational statistics, which focuses on making predictions using computers; but not all machine learning is statistical learning. The study of mathematical optimization delivers methods, theory and application domains to the field of machine learning.

Data mining is a related field of study, focusing on exploratory data analysis through unsupervised learning. Some implementations of machine learning use data and neural networks in a way that mimics the working of a biological brain. In its application across business problems, machine learning is also referred to as predictive analytics.

Machine learning is the study of computer algorithms that can improve automatically through experience and by the use of data. Machine learning algorithms build a model based on sample data, known as training data, in order to make predictions or decisions without being explicitly programmed to do so. For example, providing real-time decision support for incident management can help emergency responders in saving lives as well as reducing incident recovery time. Various algorithms for self-driving cars are another example of machine learning that already begins to significantly affect the transportation system.
In this case, the car collects data through various sensors and takes driving decisions to provide safe and efficient travel experience to passengers. In both cases, machine learning methods search through several data sets and utilize complex algorithms to identify patterns, take decisions, and/or predict future trends. Supervised learning, also known as supervised machine learning, is defined by its use of labeled datasets to train algorithms that to classify data or predict outcomes accurately. As input data is fed into the model, it adjusts its weights until the model has been fitted appropriately.

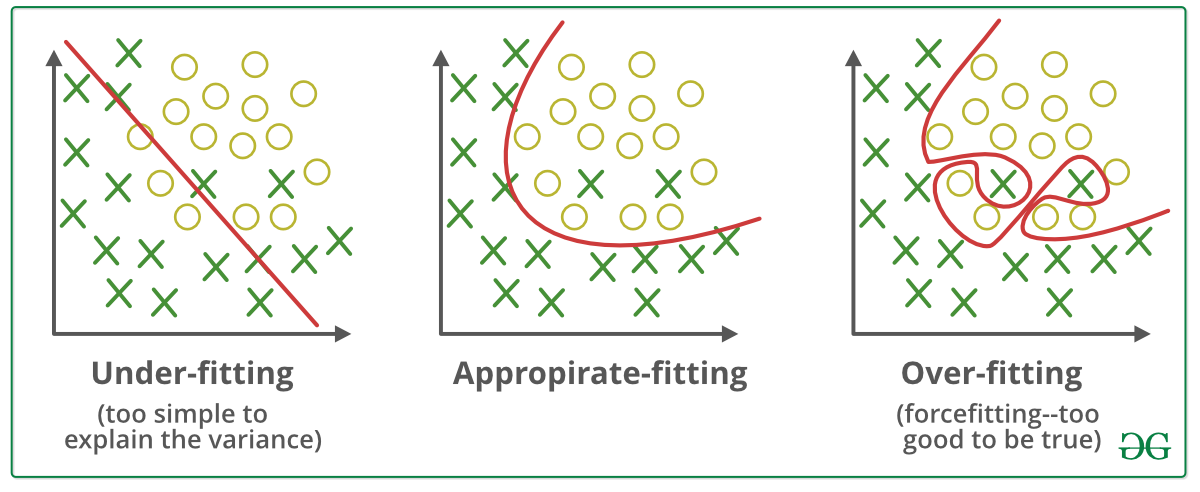
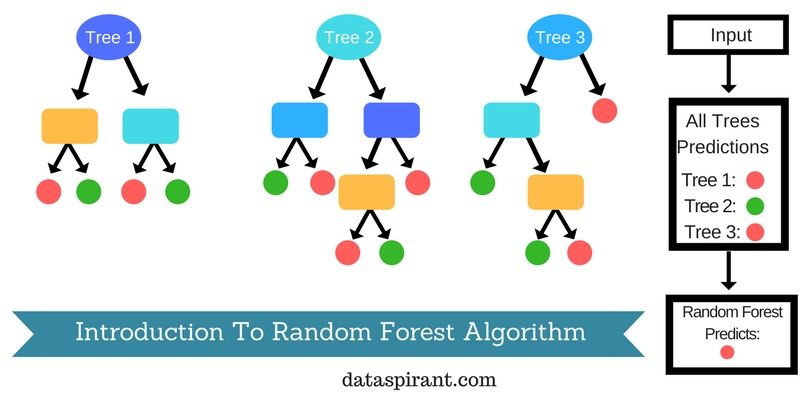
This occurs as part of the cross validation process to ensure that the model avoids overfitting or underfitting. Supervised learning helps organizations solve for a variety of real-world problems at scale, such as classifying spam in a separate folder from your inbox. Some methods used in supervised learning include neural networks, naïve bayes, linear regression, logistic regression, random forest, support vector machine , and more. It is focused on teaching computers to learn from data and to improve with experience – instead of being explicitly programmed to do so. In machine learning, algorithms are trained to find patterns and correlations in large data sets and to make the best decisions and predictions based on that analysis. Machine learning applications improve with use and become more accurate the more data they have access to.
Applications of machine learning are all around us –in our homes, our shopping carts, our entertainment media, and our healthcare. Reinforcement learning is an algorithm that helps the program understand what it is doing well. Often classified as semi-supervised learning, reinforcement learning is when a machine is told what it is doing correctly so it continues to do the same kind of work. This semi-supervised learning helps neural networks and machine learning algorithms identify when they have gotten part of the puzzle correct, encouraging them to try that same pattern or sequence again.

Sometimes reinforcement learning is given an output, sometimes it is not. The real goal of reinforcement learning is to help the machine or program understand the correct path so it can replicate it later. They seek to identify a set of context-dependent rules that collectively store and apply knowledge in a piecewise manner in order to make predictions. In supervised learning algorithms, the machine is taught by example. Supervised learning models consist of "input" and "output" data pairs, where the output is labeled with the desired value.

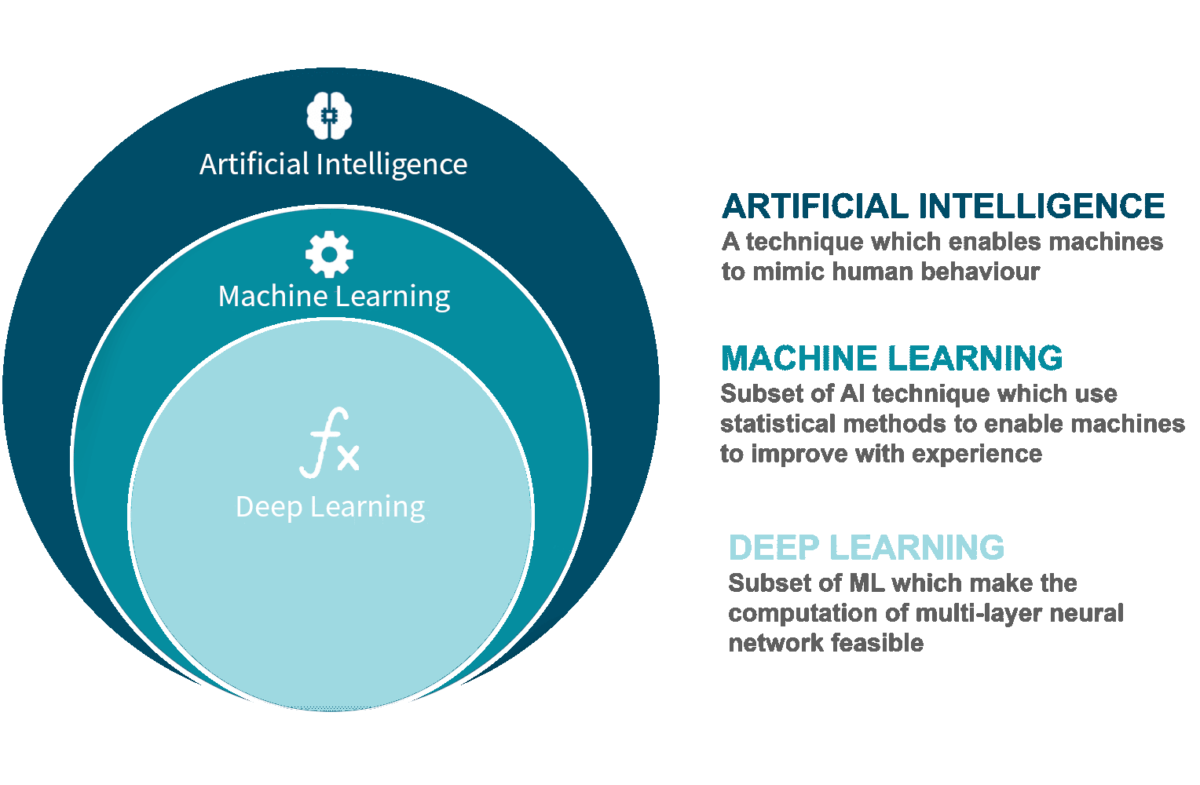
For example, let's say the goal is for the machine to tell the difference between daisies and pansies. One binary input data pair includes both an image of a daisy and an image of a pansy. The desired outcome for that particular pair is to pick the daisy, so it will be pre-identified as the correct outcome. Machine learning – and its components of deep learning and neural networks – all fit as concentric subsets of AI.

Machine learning algorithms allow AI to not only process that data, but to use it to learn and get smarter, without needing any additional programming. Artificial intelligence is the parent of all the machine learning subsets beneath it. Within the first subset is machine learning; within that is deep learning, and then neural networks within that.

The systems that use this method are able to considerably improve learning accuracy. Usually, semi-supervised learning is chosen when the acquired labeled data requires skilled and relevant resources in order to train it / learn from it. Otherwise, acquiring unlabeled data generally doesn't require additional resources.

Supervised machine learning algorithms can apply what has been learned in the past to new data using labeled examples to predict future events. Starting from the analysis of a known training dataset, the learning algorithm produces an inferred function to make predictions about the output values. The system is able to provide targets for any new input after sufficient training. The learning algorithm can also compare its output with the correct, intended output and find errors in order to modify the model accordingly. With the help of sample historical data, which is known as training data, machine learning algorithms build a mathematical model that helps in making predictions or decisions without being explicitly programmed.

Machine learning brings computer science and statistics together for creating predictive models. Machine learning constructs or uses the algorithms that learn from historical data. The more we will provide the information, the higher will be the performance. Imagine the company Tesla using a deep learning algorithm for its cars to recognize STOP signs. In the first step, the ANN would identify the relevant properties of the STOP sign, also called features.

Features may be specific structures in the inputted image, such as points, edges, or objects. While a software engineer would have to select the relevant features in a more traditional machine learning algorithm, the ANN is capable of automatic feature engineering. When fed with training data, the deep learning algorithms would eventually learn from their own errors whether the prediction was good, or whether it needs to adjust. "Deep" machine learning can leverage labeled datasets, also known as supervised learning, to inform its algorithm, but it doesn't necessarily require a labeled dataset. It can ingest unstructured data in its raw form (e.g. text, images), and it can automatically determine the set of features which distinguish different categories of data from one another.

Unlike machine learning, it doesn't require human intervention to process data, allowing us to scale machine learning in more interesting ways. Deep learning and neural networks are primarily credited with accelerating progress in areas, such as computer vision, natural language processing, and speech recognition. Unsupervised learning algorithms take a set of data that contains only inputs, and find structure in the data, like grouping or clustering of data points. The algorithms, therefore, learn from test data that has not been labeled, classified or categorized. Instead of responding to feedback, unsupervised learning algorithms identify commonalities in the data and react based on the presence or absence of such commonalities in each new piece of data. A central application of unsupervised learning is in the field of density estimation in statistics, such as finding the probability density function.

Though unsupervised learning encompasses other domains involving summarizing and explaining data features. As you have seen, the use of machine learning algorithms has many benefits. Systems that are based on this type of algorithm are more versatile and are capable of working in changing environments and adapting to them. You can perform tasks and solve problems related to computer vision, robotics and data analysis, among many others, which, until the appearance of these algorithms, was unthinkable. All this makes machine learning applications a great ally of Industry 4.0 when it comes to automating processes.

Deep learning is a machine learning method that relies on artificial neural networks, allowing computer systems to learn by example. In most cases, deep learning algorithms are based on information patterns found in biological nervous systems. First and foremost, while traditional machine learning algorithms have a rather simple structure, such as linear regression or a decision tree, deep learning is based on an artificial neural network. This multi-layered ANN is, like a human brain, complex and intertwined. Semi-Supervised Learning as the name suggests, it's a combination of the worlds of supervised and unsupervised learning algorithms. It uses a small amount of labeled data and a large amount of unlabeled data.
The major contribution of these algorithms is that they provide improved efficiency to the unsupervised learning models. And not only that, they are able to add a layer of control for the Unsupervised Models. Unsupervised learning involves just giving the machine the input, and letting it come up with the output based on the patterns it can find. This kind of machine learning algorithm tends to have more errors, simply because you aren't telling the program what the answer is. But unsupervised learning helps machines learn and improve based on what they observe.

Algorithms in unsupervised learning are less complex, as the human intervention is less important. Machines are entrusted to do the data science work in unsupervised learning. Semi-supervised learning is the third of four machine learning models. In a perfect world, all data would be structured and labeled before being input into a system. But since that is obviously not feasible, semi-supervised learning becomes a workable solution when vast amounts of raw, unstructured data are present. This model consists of inputting small amounts of labeled data to augment unlabeled data sets.

Essentially, the labeled data acts to give a running start to the system and can considerably improve learning speed and accuracy. A semi-supervised learning algorithm instructs the machine to analyze the labeled data for correlative properties that could be applied to the unlabeled data. In contrast, unsupervised machine learning algorithms are used when the information used to train is neither classified nor labeled. Unsupervised learning studies how systems can infer a function to describe a hidden structure from unlabeled data. The system doesn't figure out the right output, but it explores the data and can draw inferences from datasets to describe hidden structures from unlabeled data.

Since the 2010s, advances in both machine learning algorithms and computer hardware have led to more efficient methods for training deep neural networks that contain many layers of non-linear hidden units. By 2019, graphic processing units , often with AI-specific enhancements, had displaced CPUs as the dominant method of training large-scale commercial cloud AI. Reinforcement learning is an area of machine learning concerned with how software agents ought to take actions in an environment so as to maximize some notion of cumulative reward. In machine learning, the environment is typically represented as a Markov decision process .

Many reinforcement learning algorithms use dynamic programming techniques. Reinforcement learning algorithms do not assume knowledge of an exact mathematical model of the MDP, and are used when exact models are infeasible. Reinforcement learning algorithms are used in autonomous vehicles or in learning to play a game against a human opponent. A deep learning model is designed to continually analyze data with a logical structure similar to how a human would draw conclusions.

To complete this analysis, deep learning applications use a layered structure of algorithms called an artificial neural network. The design of an artificial neural network is inspired by the biological network of neurons in the human brain, leading to a learning system that's far more capable than that of standard machine learning models. Rule-based machine learning is a general term for any machine learning method that identifies, learns, or evolves "rules" to store, manipulate or apply knowledge. The defining characteristic of a rule-based machine learning algorithm is the identification and utilization of a set of relational rules that collectively represent the knowledge captured by the system.
This is in contrast to other machine learning algorithms that commonly identify a singular model that can be universally applied to any instance in order to make a prediction. Rule-based machine learning approaches include learning classifier systems, association rule learning, and artificial immune systems. A few years ago a branch of machine learning emerged that is known as deep learning or Deep learning. Machine learning algorithms are based on regression equations and decision trees, among others. However, Deep learning algorithms use what are known as neural networks that in a way try to mimic the functioning of neurons in living organisms. They are a set of neurons connected to each other and that perform mathematical operations to extract parameters and characteristics, to finally obtain a classification result.

This type of machine learning algorithms allow to detect patterns and classify new data from the trained models. Examples of supervised machine learning include algorithms such as linear and logistic regression, multiclass classification, and support vector machines. Unsupervised Machine Learning Unsupervised machine learning uses a more independent approach, in which a computer learns to identify complex processes and patterns without a human providing close, constant guidance.
Unsupervised machine learning involves training based on data that does not have labels or a specific, defined output. Supervised Machine Learning Supervised machine learning algorithms are the most commonly used. With this model, a data scientist acts as a guide and teaches the algorithm what conclusions it should make.

Just as a child learns to identify fruits by memorizing them in a picture book, in supervised learning, the algorithm is trained by a dataset that is already labeled and has a predefined output. While basic machine learning models do become progressively better at performing their specific functions as they take in new data, they still need some human intervention. If an AI algorithm returns an inaccurate prediction, then an engineer has to step in and make adjustments. With a deep learning model, an algorithm can determine whether or not a prediction is accurate through its own neural network—no human help is required.

The value of ML is beginning to show itself; things like tagging objects and people inside photos are machine learning at play. In video applications like YouTube, recommending the next video to watch is also powered by machine learning. The most used Google search engine has many machine learning systems at its core, from understanding the text of your query to adjusting the results based on your interests. Today, machine learning applications are already quite wide-ranging, including image recognition, fraud detection, and recommendation systems.





No comments:
Post a Comment
Note: Only a member of this blog may post a comment.